Fun with Variational Autoencoders
This is a starter kernel to use Labelled Faces in the Wild (LFW) Dataset in order to maintain knowledge about main Autoencoder principles. PyTorch will be used for modelling.
This kernel will not update for a while for the purpose of training by yourself.
Fork it and give it an upvote.
Useful links:
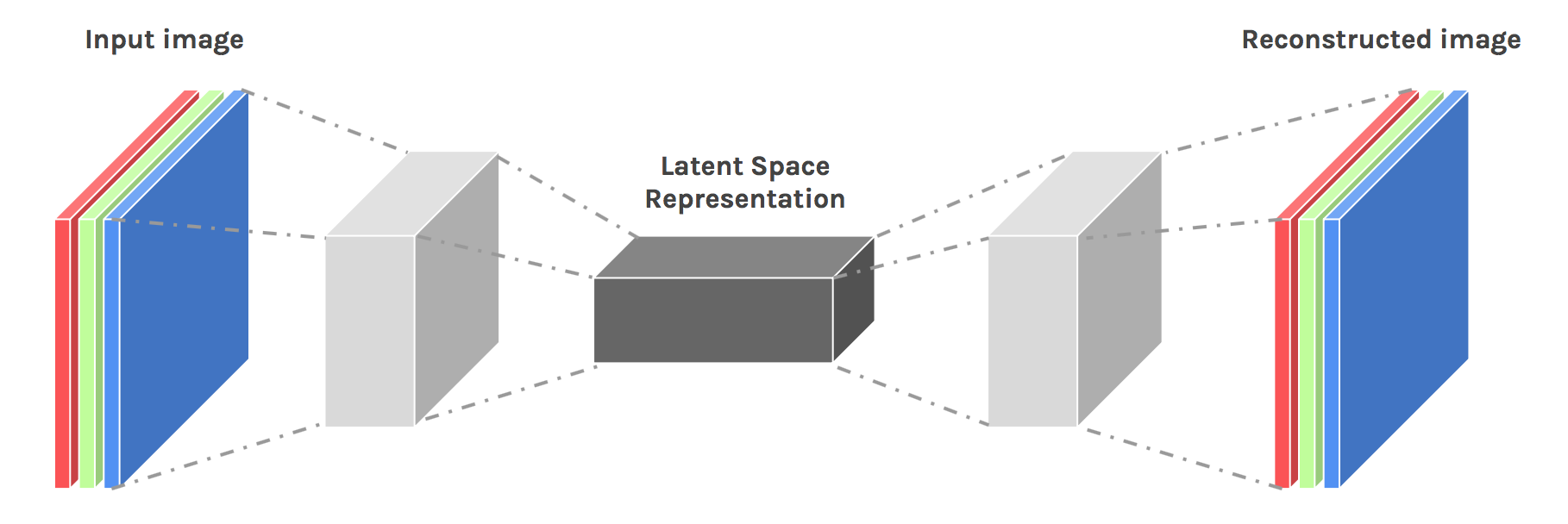
A bit of theory
"Autoencoding" is a data compression algorithm where the compression and decompression functions are 1) data-specific, 2) lossy, and 3) learned automatically from examples rather than engineered by a human. Additionally, in almost all contexts where the term "autoencoder" is used, the compression and decompression functions are implemented with neural networks.
-
Autoencoders are data-specific, which means that they will only be able to compress data similar to what they have been trained on. This is different from, say, the MPEG-2 Audio Layer III (MP3) compression algorithm, which only holds assumptions about "sound" in general, but not about specific types of sounds. An autoencoder trained on pictures of faces would do a rather poor job of compressing pictures of trees, because the features it would learn would be face-specific.
-
Autoencoders are lossy, which means that the decompressed outputs will be degraded compared to the original inputs (similar to MP3 or JPEG compression). This differs from lossless arithmetic compression.
-
Autoencoders are learned automatically from data examples, which is a useful property: it means that it is easy to train specialized instances of the algorithm that will perform well on a specific type of input. It doesn't require any new engineering, just appropriate training data.
source: https://blog.keras.io/building-autoencoders-in-keras.html
import matplotlib.pyplot as plt
import os
import glob
import pandas as pd
import random
import numpy as np
import cv2
import base64
import imageio
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data_utils
!pip install opencv2 --upgrade --quiet
from copy import deepcopy
from torch.autograd import Variable
from tqdm import tqdm
from pprint import pprint
from PIL import Image
from sklearn.model_selection import train_test_split
import os---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
/tmp/ipykernel_56/2930133908.py in <module>
5 import random
6 import numpy as np
----> 7 import cv2
8 import base64
9 import imageio
ModuleNotFoundError: No module named 'cv2'DATASET_PATH ="/kaggle/input/lfw-dataset/lfw-deepfunneled/lfw-deepfunneled/"
ATTRIBUTES_PATH = "/kaggle/input/lfw-attributes/lfw_attributes.txt"
DEVICE = torch.device("cuda")---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_56/625683825.py in <module>
1 DATASET_PATH ="/kaggle/input/lfw-dataset/lfw-deepfunneled/lfw-deepfunneled/"
2 ATTRIBUTES_PATH = "/kaggle/input/lfw-attributes/lfw_attributes.txt"
----> 3 DEVICE = torch.device("cuda")
NameError: name 'torch' is not defined