Learn practical skills, build real-world projects, and advance your career
Updated a year ago
Movie Rating Prediction Using Neural Collaborative Filtering
!pip install jovian --upgrade -q
import jovian
jovian.set_project('movielens-fastai-5f4bd')
jovian.set_colab_id('1pbthqcBA3uqfqjTBSruKMsvoI1jz6str')
!pip install torchvision
import torchLooking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: torchvision in /usr/local/lib/python3.7/dist-packages (0.13.1+cu113)
Requirement already satisfied: torch==1.12.1 in /usr/local/lib/python3.7/dist-packages (from torchvision) (1.12.1+cu113)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torchvision) (4.1.1)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from torchvision) (2.23.0)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.7/dist-packages (from torchvision) (7.1.2)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from torchvision) (1.21.6)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (2022.9.24)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (1.24.3)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (2.10)
The MovieLens 100K Dataset
The MovieLens 100K dataset is a collection of movie ratings by 943 users on 1682 movies. There are 100,000 ratings in total, since not every user has seen and rated every movie. Here are some sample ratings from the dataset:
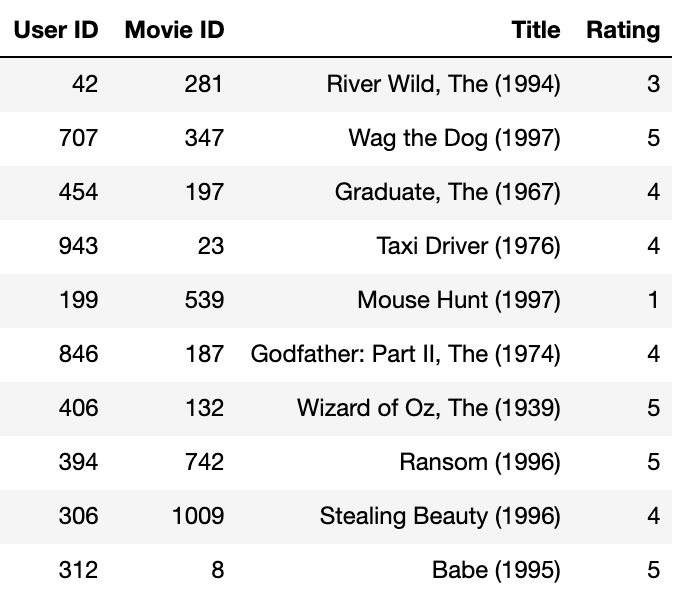
Every user is given a unique numeric ID (ranging from 1 to 943), and each movie is given a unique numeric ID too (ranging from 1 to 1682). User's ratings for movies are integers ranging from 1 to 5, with 5 being the highest.
Our objective here is to build a model that can predict how a user would rate a movie they haven't already seen, by looking at the movie ratings of other users with similar tastes.
Preparing the Data
Download the data and extract it
!pip install pandas-profiling --quiet